Getting Started with Microservices

Originally published for Codebrahma on Jul 18, 2017.
Microservices is a vague term which usually points to small independent services which together form up an application. Microservices architecture stands in contrast to Monolithic architecture, where the application is one big system. We will discuss about how to get started as a beginner and choosing the right tools for setting up microservice architechture.
Rapid Rise in popularity of Microservices
Microservices have recently risen into popularity, as suggested by this Google trends index:
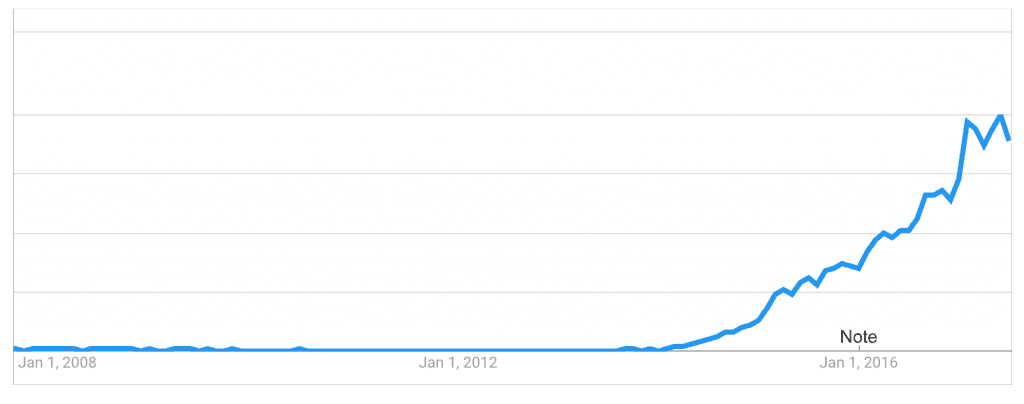
“microservices” in Google Trends
Before getting into what they are, and how to use them, let’s find out why microservices are rising into popularity even though it’s not a new concept. This can be explained by Conway’s Law which states that:
Organisations which design systems … are constrained to produce designs which are copies of the communication structures of these organisations
Until recently majority of companies were used to be giant enterprises, making equally giant enterprise software, or monoliths. Not anymore. Since last 5 years, companies are getting more distributed in nature. In fact, some of the new unicorns like Automattic and Gitlab are entirely distributed. That explains why microservices are rising in popularity.
Why Microservices?
Fewer compromises in tech stack
Choosing a tech stack is always a tough call. Skills of the team, scalability, maintenance are all important factors in this choice. But many times what’s good for one portion of the app, is not good for the other.
For example, a trading platform needs PostgreSQL due to support for transactions, the user specific data has to be stored in DynamoDB. Generally, a trade off is made. But in Microservices Architecture, each microservice owns a set of business logic and related data in the form it deem best, and provide an interface to interact with it. So there can be microservices for trades and users each, with data hosted on PostgreSQL and DynamoDB, and access to external services is allowed only through the interface. So a computation intensive microservice can be written in Python while the API Server remains in NodeJS, and so on.
A sample architecture would look like
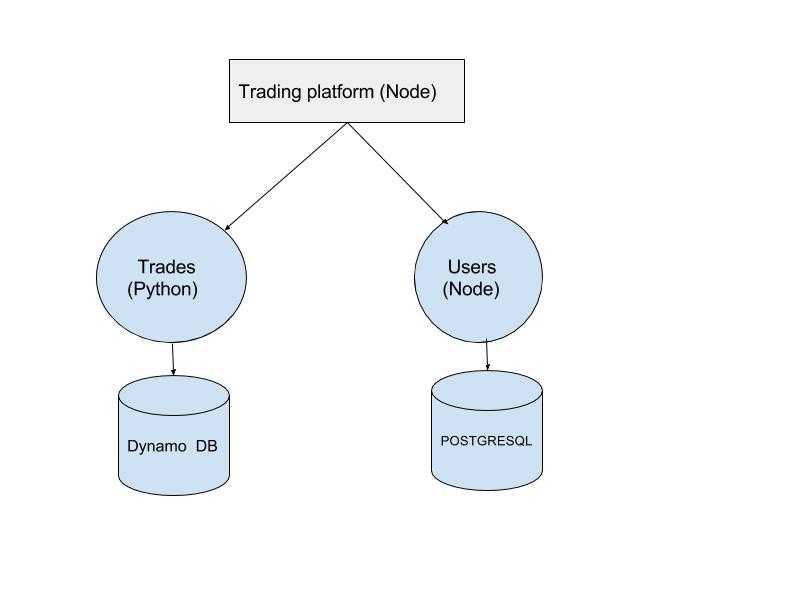
Independent teams
In a monolithic application, most of the people in a development team needs to know all the parts of the application even to develop a small feature. They have to collaborate with other teams on deployment schedules, versioning, data migrations, etc. On the other hand, in Microservices Architecture the teams just need to know the interface provided by other services and stick to the interface provided by theirs. Each microservice should be independently deployable. CI/CD tools like CirclCi, Travis and Heroku are of great help while developing microservices. To develop/maintain a service, a small team with limited knowledge is enough.
Do one thing and do it well
Microservices Architecture also resembles the Unix philosophy’s principle, Do one thing and do it well. It is a principle which has proved it’s worthiness and is one of the reasons Unix-like systems are not obsolete even after decades. Microservices should be designed to do one thing, tested to handle all the possible scenarios and then “piped” together to form a robust and flexible application.
Fault isolation
Imagine error in a report generation module, takes the full trading application down. It’s terrible and unnecessary. If the application is based on microservices, the report generation module will fail, taking down only that specific feature. Users who are not generating reports won’t even notice, and the critical parts of the application will still be working. That’s a result of Loose coupling between microservices, now achievable through this architecture.
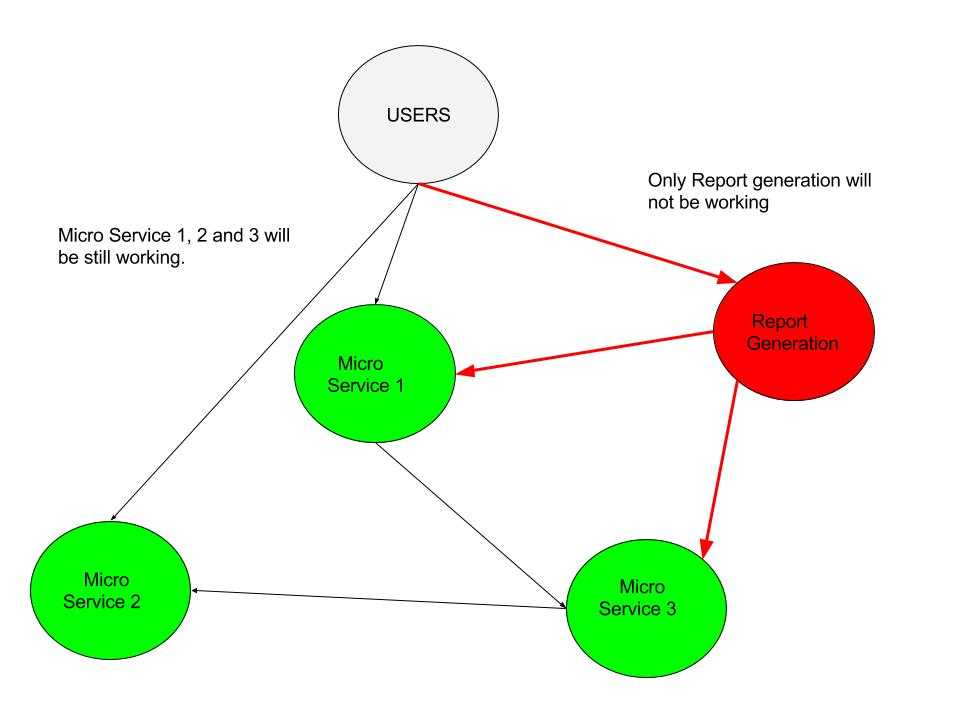
How to develop Microservices?
In Node.js, Seneca is a widely used framework to develop microservices. But if you want to get yours hands dirty, read on.
API Gateway
Microservices can be deployed without a main central service, but sometimes a thin central layer is usually kept to have shared libraries. Sometimes it also works as an API Gateway.
An API Gateway is used to provide a consistent API to the client side irrespective of the backend service, and vice versa. It is helpful when you have multiple microservices catering to clients like mobile, web, other servers, etc. Also it prevents client to make requests to multiple services by abstracting it into one request.
Inter-service communication
How should these services communicate to each other?
HTTP: Well, there are plenty of options. Most straightforward is to use HTTP/HTTPS and the interface can be made as RESTful APIs. Though, HTTP makes service discovery difficult and less dynamic. That’s a reason I don’t prefer it.
Message Queues: Message Queuing protocols like AMQP, STOMP and MQTT allows the use of publish subscribe pattern for communication between microservices. Services like RabbitMQ and Apache Kafka are widely used for this purpose. I personally prefer using Message Queues as they are fault tolerant and support message persistence.
microservice-template is a basic boilerplate which we use in our projects based on Microservices. It’s in Node and has MongoDB configured as a data store. It connects to RabbitMQ for inter-service communication via servicebus. Here’s how it looks in it’s bare minimum:
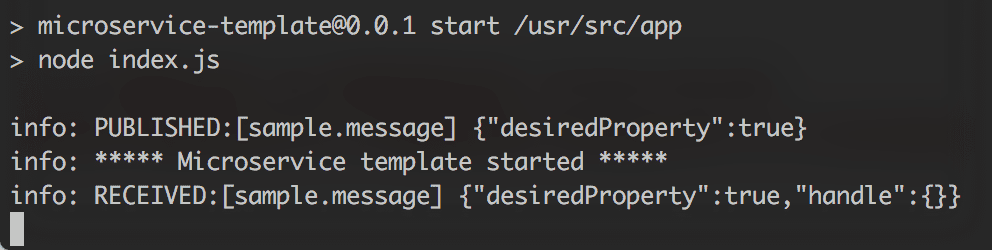
Microservice booting up and communicating
There are other concepts like Event Sourcing and CQRS which complement the Microservices Architecture. Event Sourcing is basically storing the changes to the data, instead of the changed state of the data. in a highly concurrent environment, event sourcing brings consistency of a higher order.
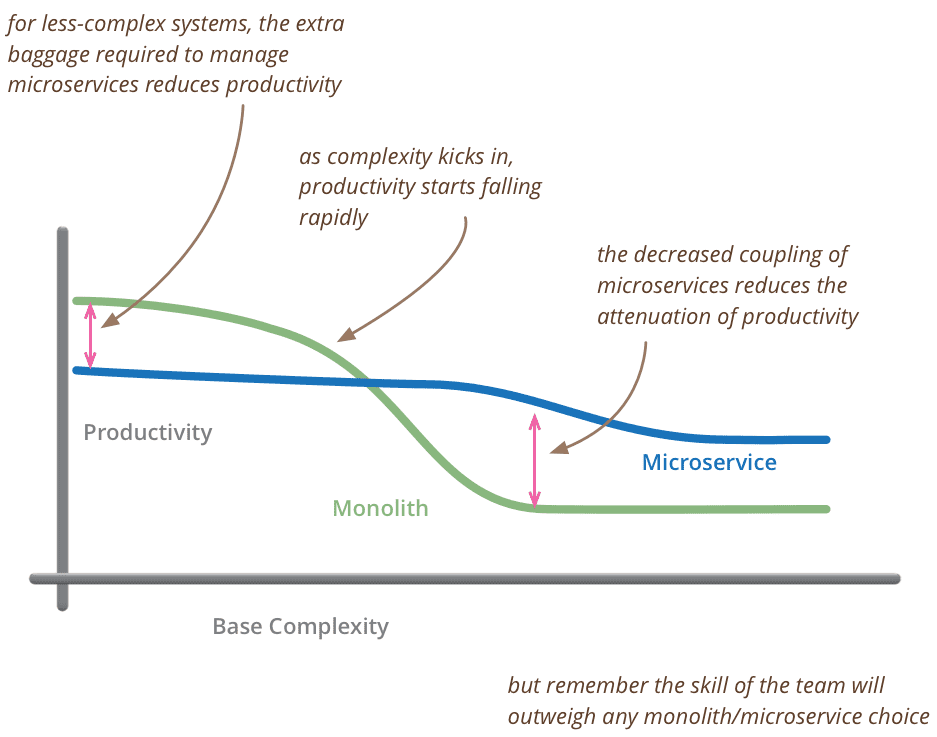
Productivity in Microservices vs Monolothic Architecture Source: Martin Fowler
But truth be told, Microservices Architecture is no silver bullet. Using microservices for fairly small apps can lead to loss in productivity, as evident in the above graph.
❤️ code